This page examines a single-factor within-subjects (repeated measures) design using raw data input, focusing on comparisons and contrasts.
Preliminary Tasks
Summary Statistics
This code obtains the descriptive statistics for the data frame.
(RepeatedData) |> describeMoments()
Summary Statistics for the Data
N M SD Skew Kurt
Outcome1 10.000 8.000 1.414 0.000 -0.738
Outcome2 10.000 11.000 2.211 -0.617 -0.212
Outcome3 10.000 12.000 2.449 0.340 -1.102This code will display the correlations among the variables.
(RepeatedData) |> describeCorrelations()
Correlations for the Data
Outcome1 Outcome2 Outcome3
Outcome1 1.000 0.533 0.385
Outcome2 0.533 1.000 0.574
Outcome3 0.385 0.574 1.000 Analyses of the Means
This section produces analyses that are equivalent to one-sample analyses separately for each level of a factor.
Confidence Intervals
This code will provide a table of confidence intervals for each level of the factor.
(RepeatedData) |> estimateMeans()
Confidence Intervals for the Means
Est SE df LL UL
Outcome1 8.000 0.447 9.000 6.988 9.012
Outcome2 11.000 0.699 9.000 9.418 12.582
Outcome3 12.000 0.775 9.000 10.248 13.752This code will produce a graph of the confidence intervals for each level of the factor.
(RepeatedData) |> plotMeans()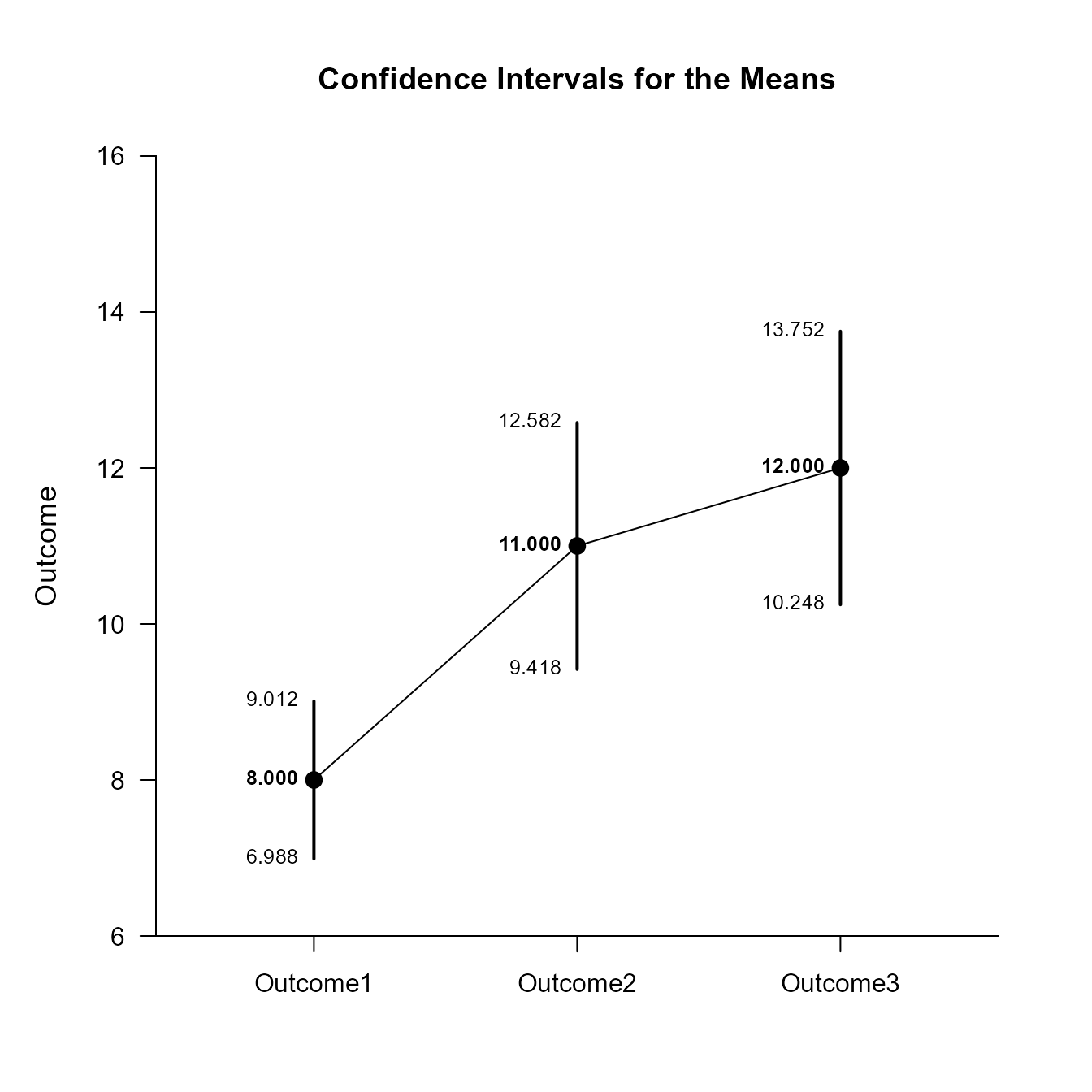
The code defaults to 95% confidence intervals. This can be changed if desired.
(RepeatedData) |> estimateMeans(conf.level = .99)
Confidence Intervals for the Means
Est SE df LL UL
Outcome1 8.000 0.447 9.000 6.547 9.453
Outcome2 11.000 0.699 9.000 8.728 13.272
Outcome3 12.000 0.775 9.000 9.483 14.517For the graph, it is possible to add a comparison line to represent a population (or test) value and a region of practical equivalence in addition to changing the confidence level.
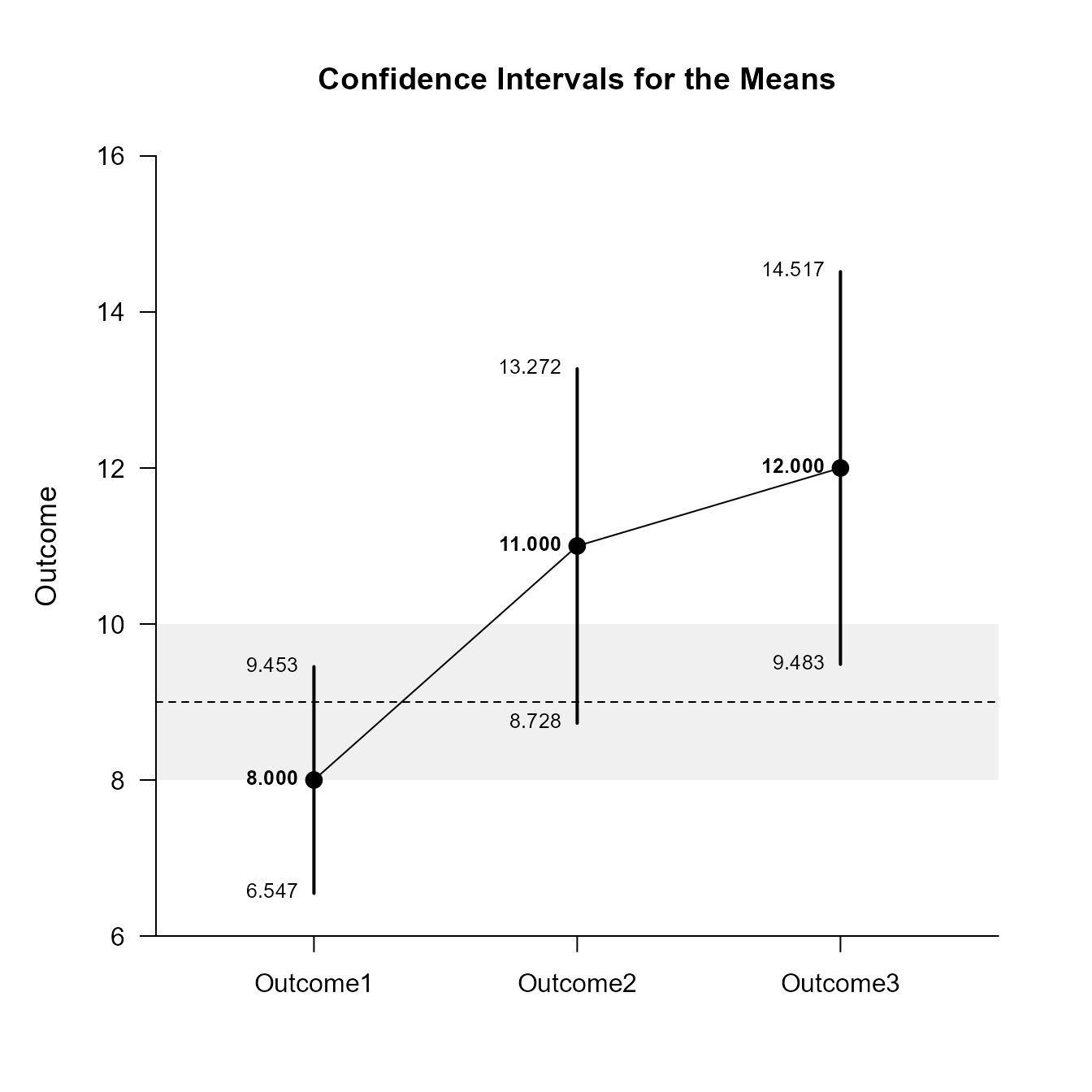
Significance Tests
This code will produce a table of NHST separately for each level of the factor. In this case, all the means are tested against a value of zero.
(RepeatedData) |> testMeans()
Hypothesis Tests for the Means
Diff SE df t p
Outcome1 8.000 0.447 9.000 17.889 0.000
Outcome2 11.000 0.699 9.000 15.732 0.000
Outcome3 12.000 0.775 9.000 15.492 0.000Often, the default test value of zero is not meaningful or plausible. This too can be altered (often in conjunction with what is presented in the plot).
(RepeatedData) |> testMeans(mu = 9)
Hypothesis Tests for the Means
Diff SE df t p
Outcome1 -1.000 0.447 9.000 -2.236 0.052
Outcome2 2.000 0.699 9.000 2.860 0.019
Outcome3 3.000 0.775 9.000 3.873 0.004Standardized Effect Sizes
This code will produce a table of standardized mean differences separately for each level of the factor. In this case, the mean is compared to zero to form the effect size.
(RepeatedData) |> standardizeMeans()
Confidence Intervals for the Standardized Means
d SE LL UL
Outcome1 5.657 1.251 3.005 8.295
Outcome2 4.975 1.111 2.622 7.312
Outcome3 4.899 1.096 2.579 7.203Here too it is possible to alter the width of the confidence intervals and to establish a more plausible comparison value for the mean.
(RepeatedData) |> standardizeMeans(mu = 9, conf.level = .99)
Confidence Intervals for the Standardized Means
d SE LL UL
Outcome1 -0.707 0.364 -1.614 0.222
Outcome2 0.905 0.384 -0.083 1.873
Outcome3 1.225 0.422 0.126 2.317Analyses of a Comparison
This section produces analyses involving comparisons of two levels of a factor.
Confidence Intervals
This code identifies the two levels for comparison and estimates the confidence interval of the difference.
(RepeatedData) |> focus(Outcome1, Outcome2) |> estimateDifference()
Confidence Interval for the Mean Difference
Est SE df LL UL
Comparison 3.000 0.596 9.000 1.651 4.349This code obtains and plots the confidence intervals for the mean difference in the identified comparison.
(RepeatedData) |> focus(Outcome1, Outcome2) |> plotDifference()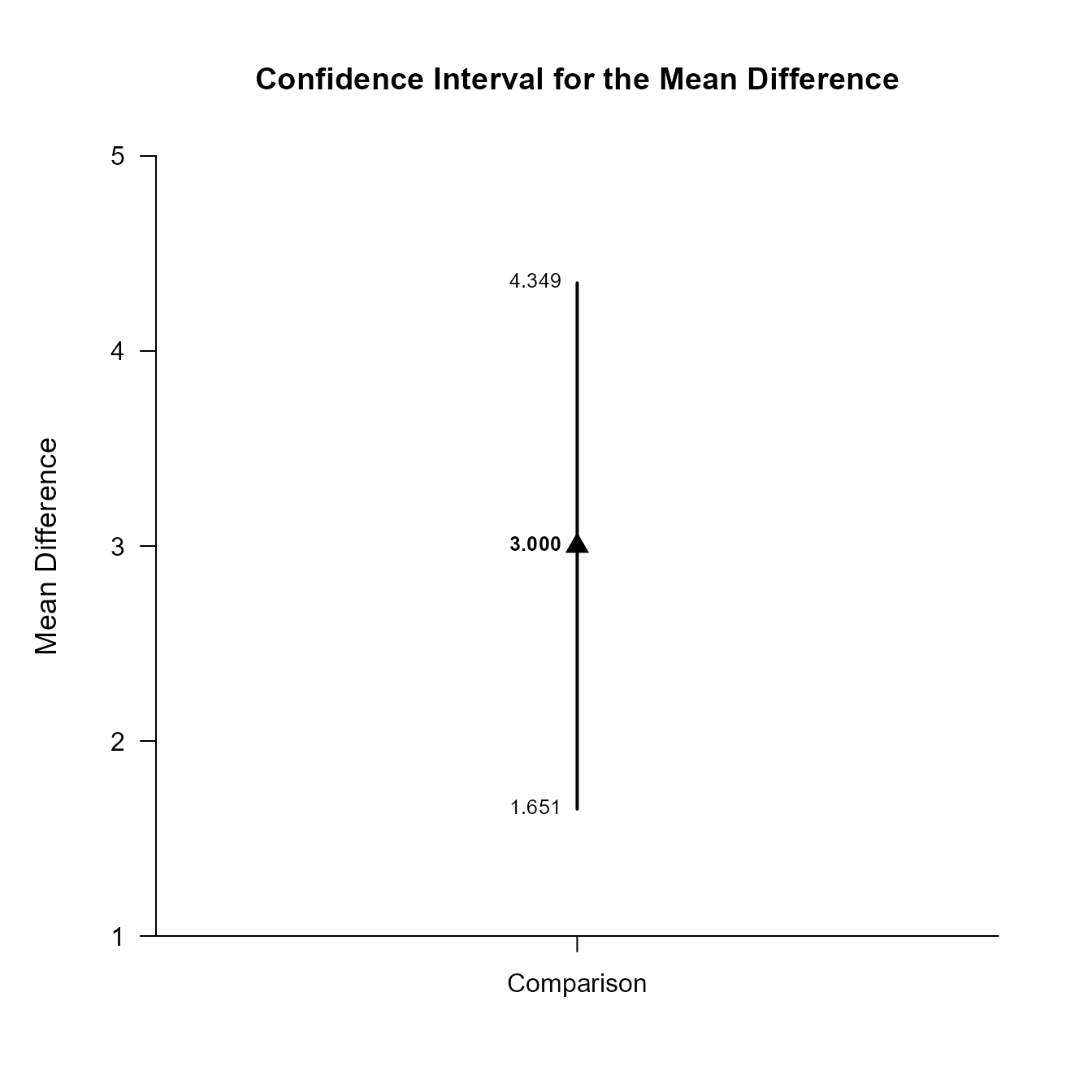
Of course, you can change the confidence level from the default 95% if desired.
(RepeatedData) |> focus(Outcome1, Outcome2) |> estimateDifference(conf.level = .99)
Confidence Interval for the Mean Difference
Est SE df LL UL
Comparison 3.000 0.596 9.000 1.062 4.938Once again, the confidence levels can be changed away from the default and a comparison line to represent a population (or test) value and a region of practical equivalence can be added to the graph..
(RepeatedData) |> focus(Outcome1, Outcome2) |> plotDifference(conf.level = .99, line = 0, rope = c(-2, 2))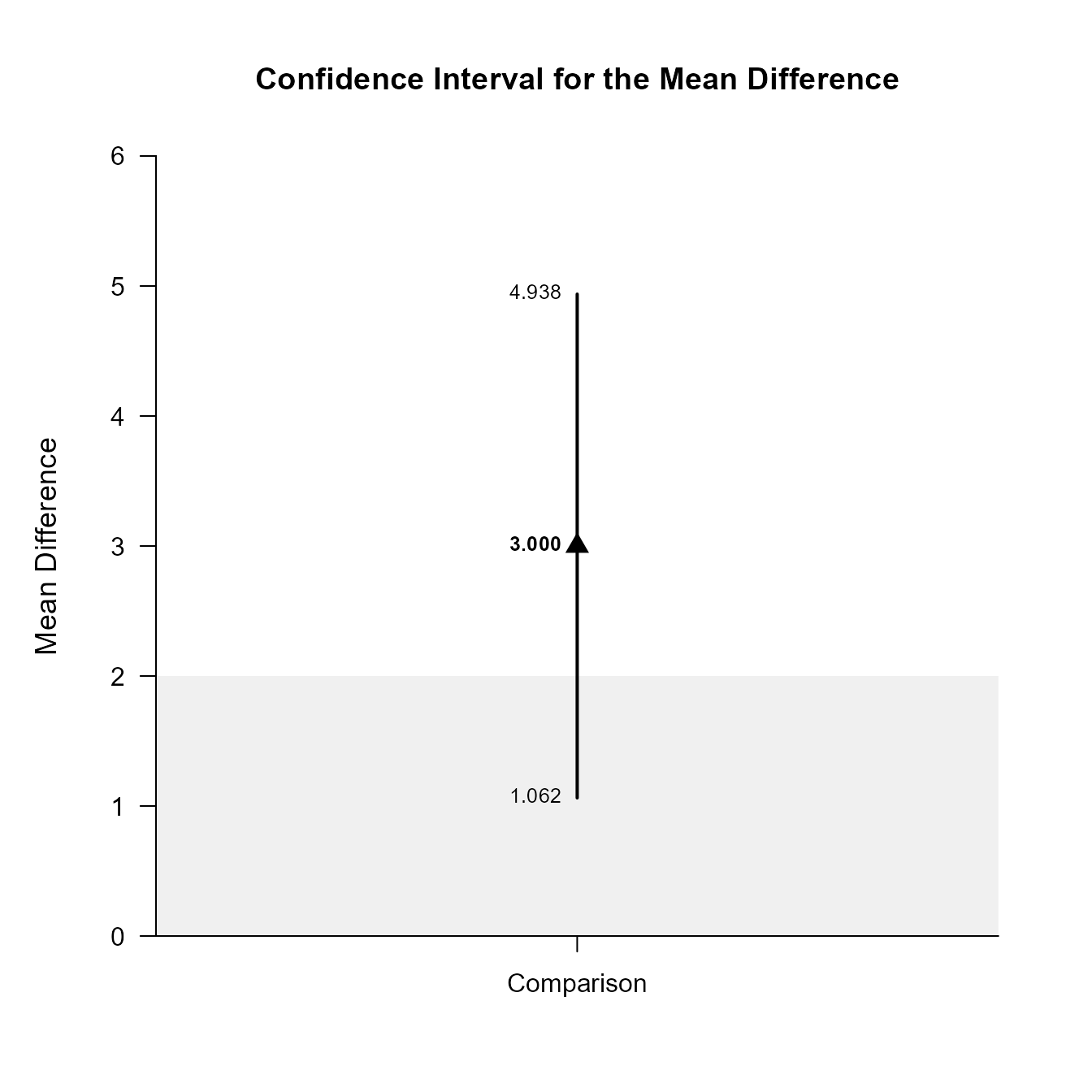
If you wish, you can get the confidence intervals for the means and the mean difference in one command.
(RepeatedData) |> focus(Outcome1, Outcome2) |> estimateComparison()
Confidence Intervals for the Mean Comparison
Est SE df LL UL
Outcome1 8.000 0.447 9.000 6.988 9.012
Outcome2 11.000 0.699 9.000 9.418 12.582
Comparison 3.000 0.596 9.000 1.651 4.349This code produces a difference plot using the confidence intervals for the means and the mean difference.
(RepeatedData) |> focus(Outcome1, Outcome2) |> plotComparison()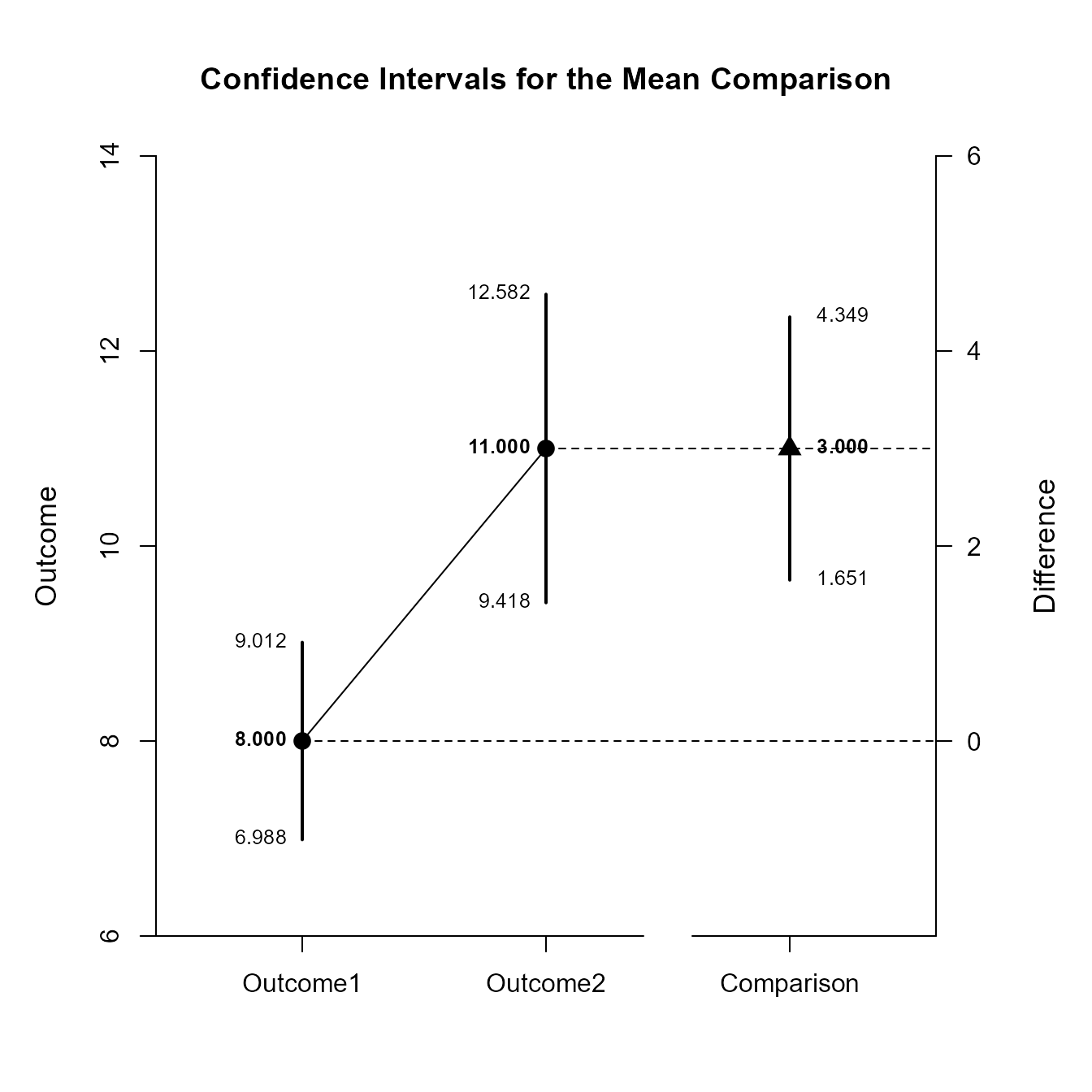
Of course, you can change the confidence level from the default 95% if desired.
(RepeatedData) |> focus(Outcome1, Outcome2) |> estimateComparison(conf.level = .99)
Confidence Intervals for the Mean Comparison
Est SE df LL UL
Outcome1 8.000 0.447 9.000 6.547 9.453
Outcome2 11.000 0.699 9.000 8.728 13.272
Comparison 3.000 0.596 9.000 1.062 4.938Once again, the confidence levels can be changed away from the default and a region of practical equivalence can be added to the graph.
(RepeatedData) |> focus(Outcome1, Outcome2) |> plotComparison(conf.level = .99, rope = c(-2, 2))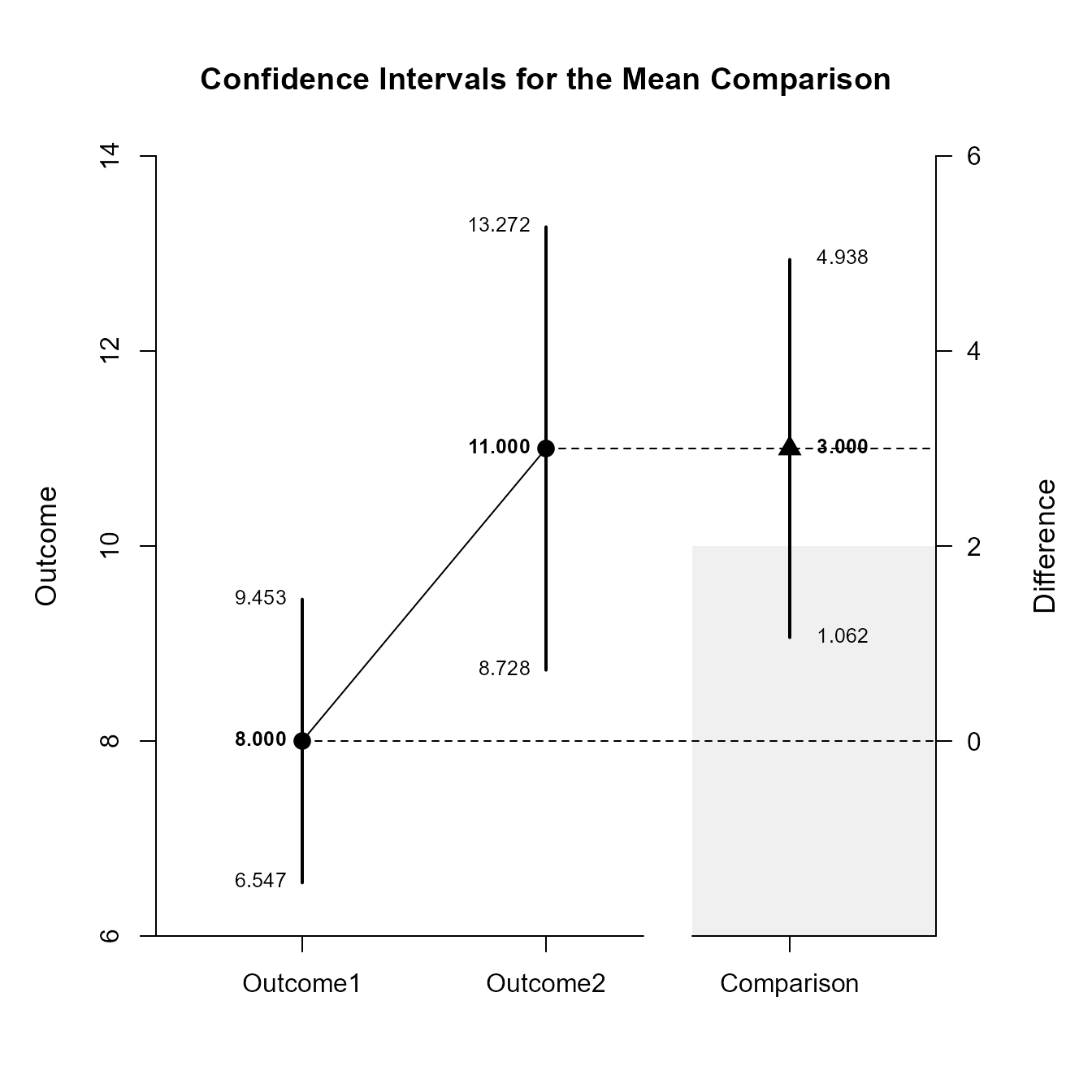
Significance Test
This code produces NHST for the identified comparison (using a default test value of zero).
(RepeatedData) |> focus(Outcome1, Outcome2) |> testDifference()
Hypothesis Test for the Mean Difference
Diff SE df t p
Comparison 3.000 0.596 9.000 5.031 0.001If the default value of zero is not plausible, it too can be changed.
(RepeatedData) |> focus(Outcome1, Outcome2) |> testDifference(mu = -2)
Hypothesis Test for the Mean Difference
Diff SE df t p
Comparison 5.000 0.596 9.000 8.385 0.000Standardized Effect Size
This code calculates a standardized mean difference for the comparison and its confidence interval.
(RepeatedData) |> focus(Outcome1, Outcome2) |> standardizeDifference()
Confidence Interval for the Standardized Mean Difference
d SE LL UL
Comparison 1.616 0.466 0.703 2.530The width of the confidence interval for the effect size can be altered if desired.
(RepeatedData) |> focus(Outcome1, Outcome2) |> standardizeDifference(conf.level = .99)
Confidence Interval for the Standardized Mean Difference
d SE LL UL
Comparison 1.616 0.466 0.416 2.816Analyses of a Contrast
This section produces analyses involving multiple levels of a factor.
Confidence Intervals
This code produces a confidence interval for a specified contrast.
(RepeatedData) |> estimateContrast(contrast = c(-1, .5, .5))
Confidence Interval for the Mean Contrast
Est SE df LL UL
Contrast 3.500 0.573 9.000 2.205 4.795This code obtains and plots the confidence intervals for the mean difference in the identified contrast.
(RepeatedData) |> plotContrast(contrast = c(-1, .5, .5))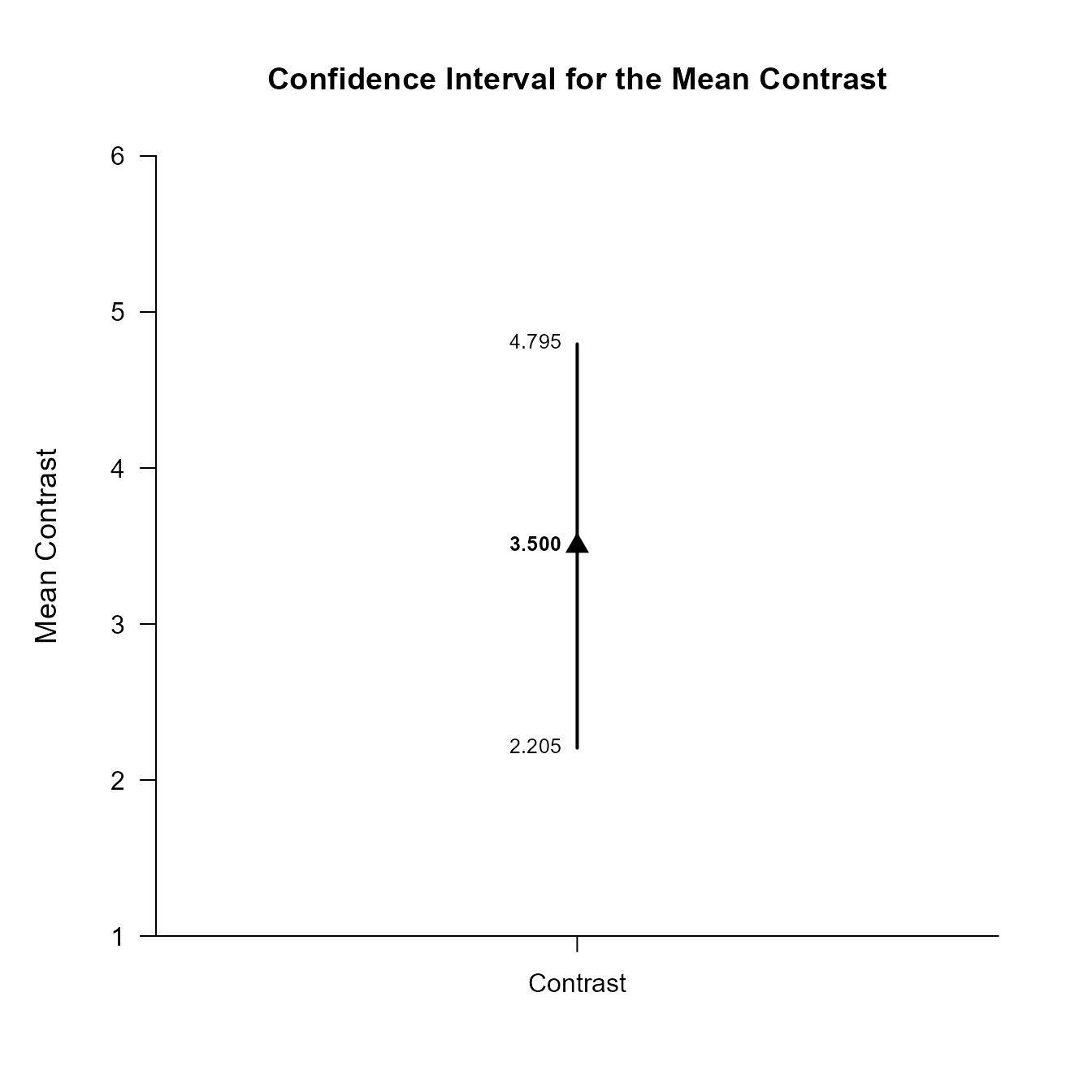
As in all other cases, the default value of the confidence interval can be changed.
(RepeatedData) |> estimateContrast(contrast = c(-1, .5, .5), conf.level = .99)
Confidence Interval for the Mean Contrast
Est SE df LL UL
Contrast 3.500 0.573 9.000 1.639 5.361The width of the confidence interval for the contrast can be altered and a comparison line to represent a population (or test) value and a region of practical equivalence can be added to the graph.
(RepeatedData) |> plotContrast(contrast = c(-1, .5, .5), conf.level = .99, line = 0, rope = c(-2, 2))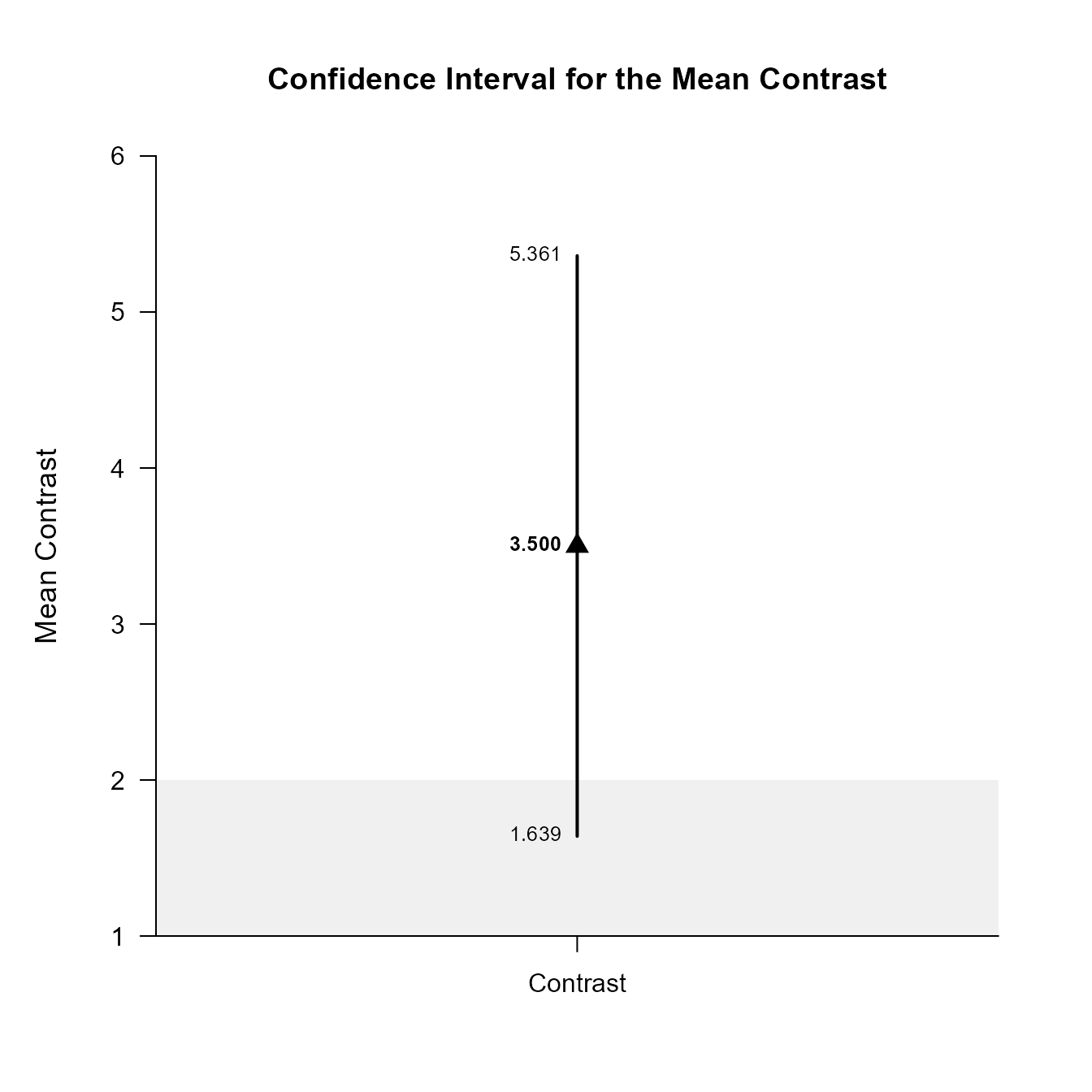
If you wish, you can get the confidence intervals for the mean subsets and the mean contrast in one command.
(RepeatedData) |> estimateSubsets(contrast = c(-1, .5, .5))
Confidence Intervals for the Mean Subsets
Est SE df LL UL
Neg Weighted 8.000 0.447 9.000 6.988 9.012
Pos Weighted 11.500 0.654 9.000 10.020 12.980
Contrast 3.500 0.573 9.000 2.205 4.795This code produces a difference plot using the confidence intervals for the mean subsets and the mean contrast.
(RepeatedData) |> plotSubsets(contrast = c(-1, .5, .5))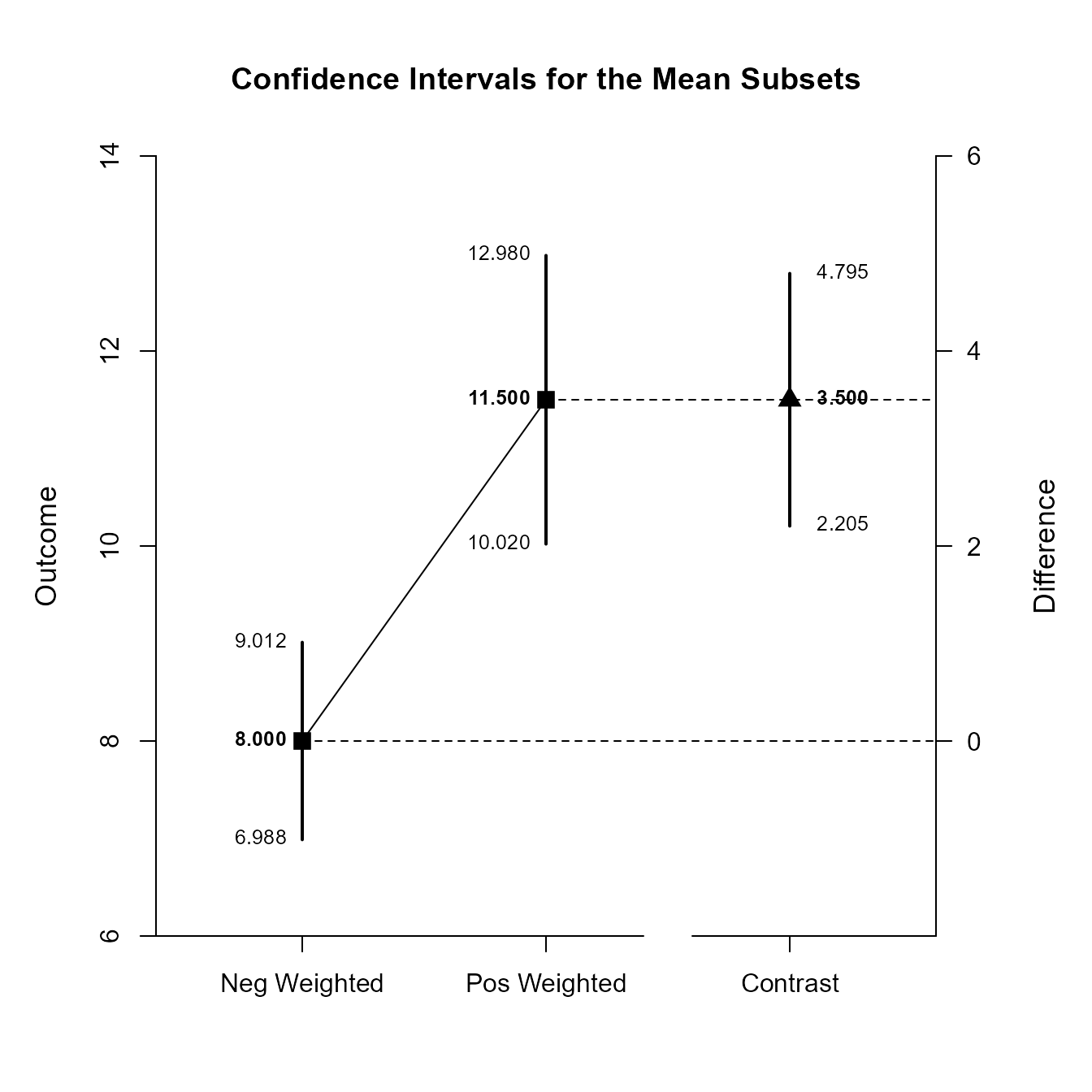
Of course, you can change the confidence level from the default 95% if desired.
(RepeatedData) |> estimateSubsets(contrast = c(-1, .5, .5), conf.level = .99)
Confidence Intervals for the Mean Subsets
Est SE df LL UL
Neg Weighted 8.000 0.447 9.000 6.547 9.453
Pos Weighted 11.500 0.654 9.000 9.374 13.626
Contrast 3.500 0.573 9.000 1.639 5.361Once again, the confidence levels can be changed away from the default and a region of practical equivalence can be added to the graph.
(RepeatedData) |> plotSubsets(contrast = c(-1, .5, .5), labels = c("Outcome1", "Others"), conf.level = .99, rope = c(-2, 2))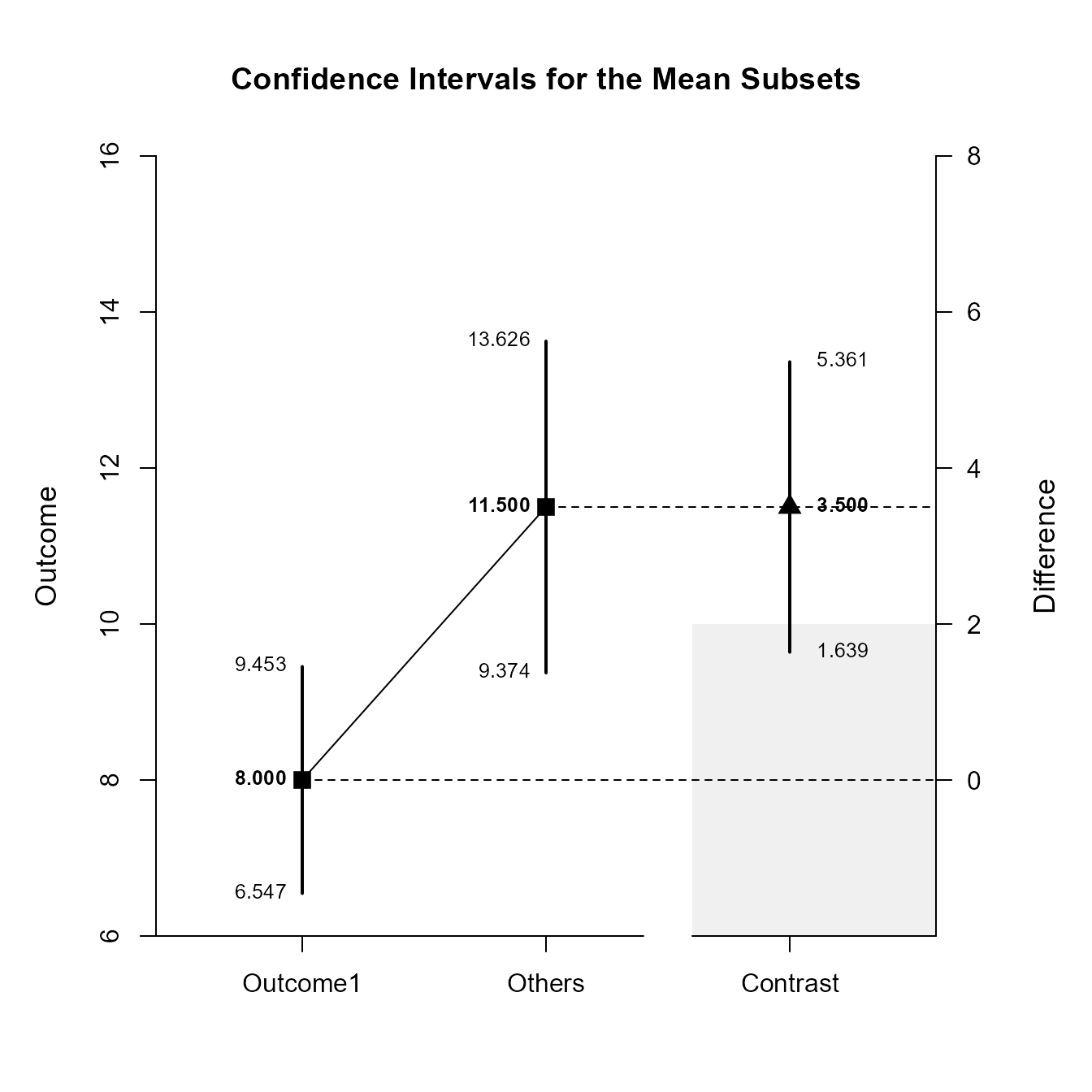
Significance Test
This code produces a NHST for the identified contrast. It tests the contrast against a value of zero by default.
(RepeatedData) |> testContrast(contrast = c(-1, .5, .5))
Hypothesis Test for the Mean Contrast
Est SE df t p
Contrast 3.500 0.573 9.000 6.113 0.000If desired, the contrast can be tested against other values.
(RepeatedData) |> testContrast(contrast = c(-1, .5, .5), mu = 4)
Hypothesis Test for the Mean Contrast
Est SE df t p
Contrast -0.500 0.573 9.000 -0.873 0.405Standardized Effect Size
This code calculates a standardized contrast and its confidence interval.
(RepeatedData) |> standardizeContrast(contrast = c(-1, .5, .5))
Confidence Interval for the Standardized Mean Contrast
Est SE LL UL
Contrast 1.689 0.371 0.962 2.415The width of the confidence interval for the effect size can be altered if desired.
(RepeatedData) |> standardizeContrast(contrast = c(-1, .5, .5), conf.level = .99)
Confidence Interval for the Standardized Mean Contrast
Est SE LL UL
Contrast 1.689 0.371 0.734 2.643Analyses of a Complex Contrast
This section examines a complex contrast among multiple means.
Confidence Intervals
Create a single contrast to compare the first variable to the grand mean (which requires some arithmetic). Then esimate and plot the contrast.
(RepeatedData) |> estimateContrast(contrast = c(2/3, -1/3, -1/3))
Confidence Interval for the Mean Contrast
Est SE df LL UL
Contrast -2.333 0.382 9.000 -3.197 -1.470
(RepeatedData) |> plotContrast(contrast = c(2/3, -1/3, -1/3))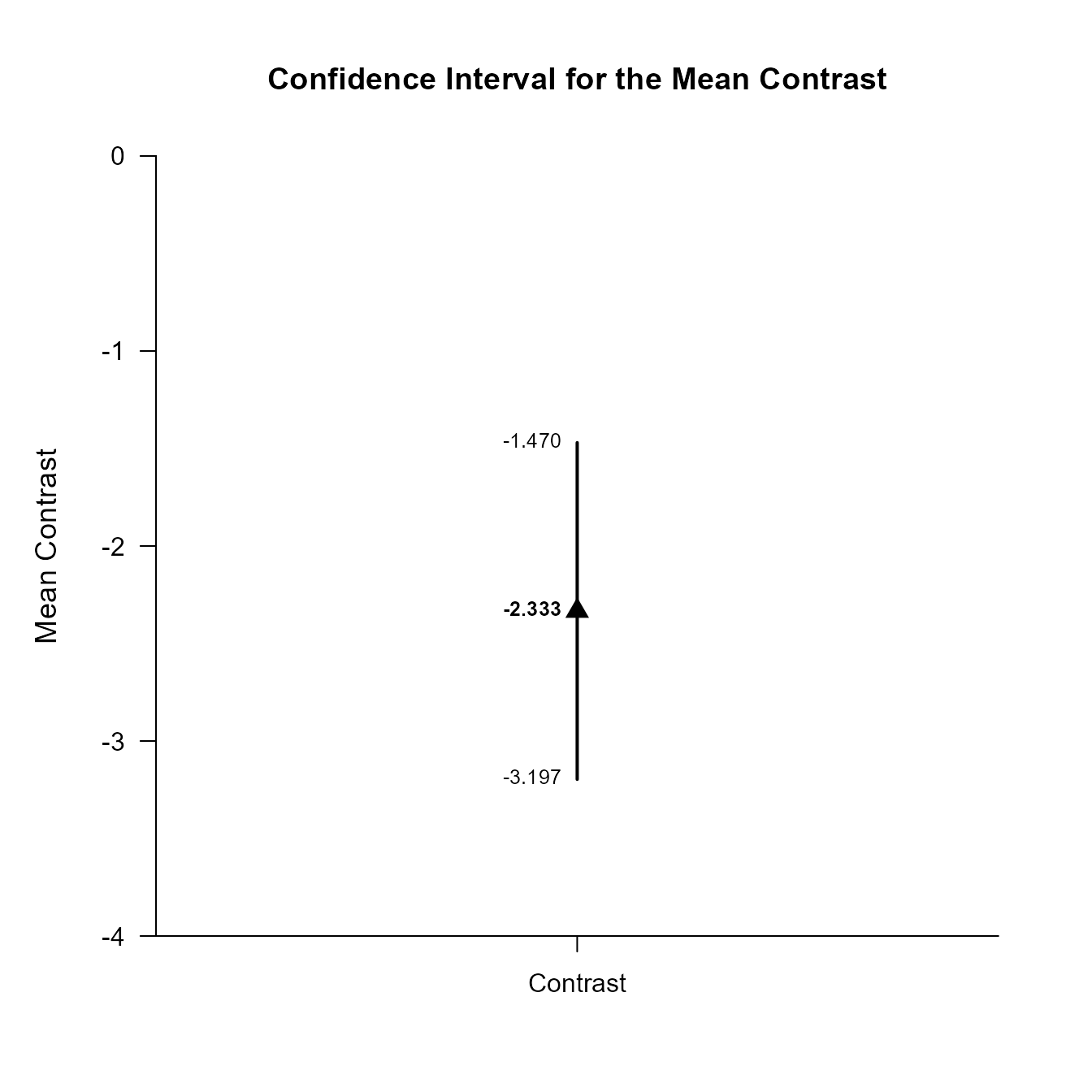
Rather than setting just one contrast, set two contrasts: one for the Grand Mean and one for Level 1. Estimate and plot the confidence intervals for each contrast and the difference between contrasts.
(RepeatedData) |> estimateComplex(contrast1 = c(1/3, 1/3, 1/3), contrast2 = c(1, 0, 0), labels = c("GrandMean", "O1Only"))
Confidence Intervals for the Mean Contrasts
Est SE df LL UL
GrandMean 10.333 0.528 9.000 9.138 11.528
O1Only 8.000 0.447 9.000 6.988 9.012
Contrast -2.333 0.382 9.000 -3.197 -1.470
(RepeatedData) |> plotComplex(contrast1 = c(1/3, 1/3, 1/3), contrast2 = c(1, 0, 0), labels = c("GrandMean", "O1Only"))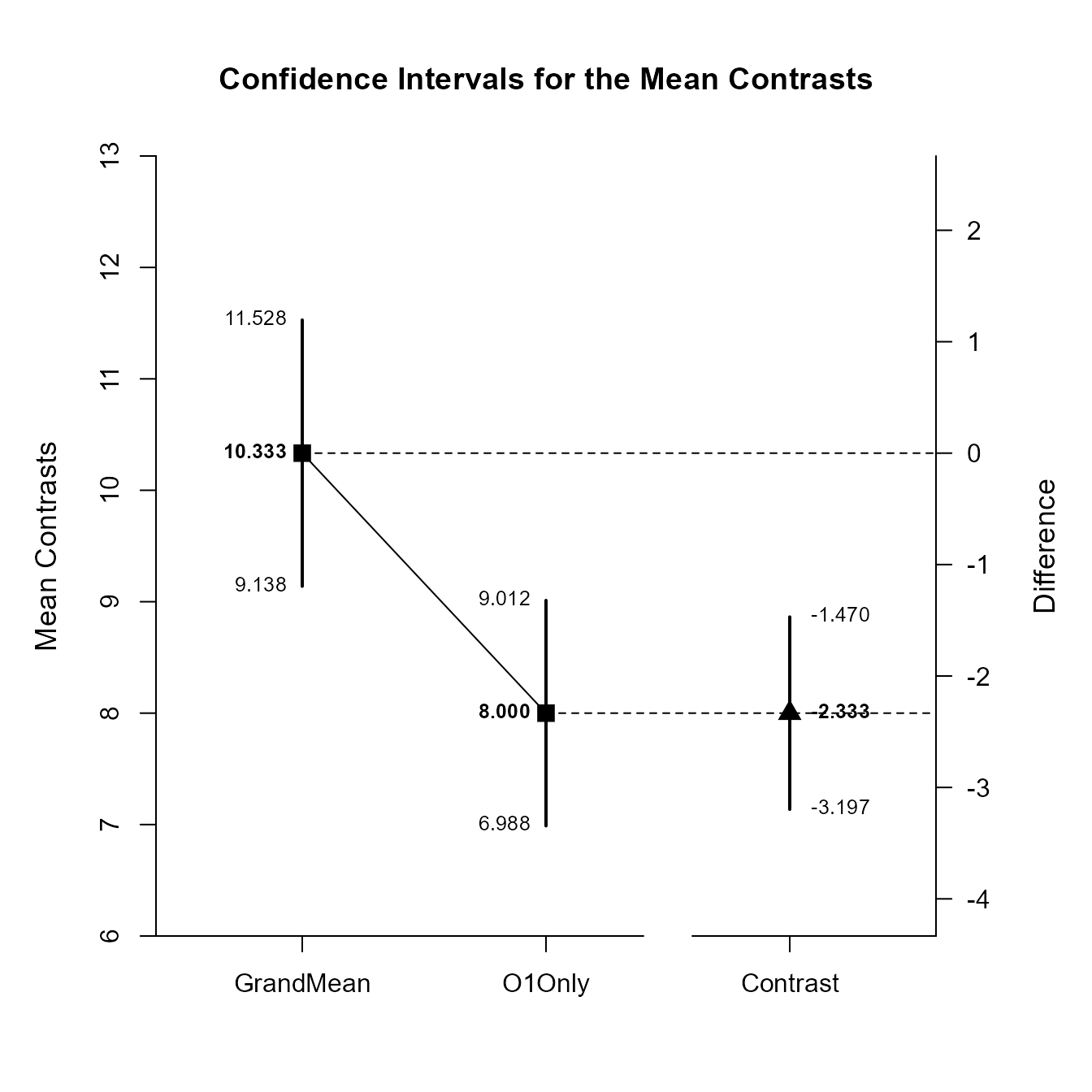
Significance Tests
The two versions of the contrast can be tested for statistical significance.
(RepeatedData) |> testContrast(contrast = c(2/3, -1/3, -1/3))
Hypothesis Test for the Mean Contrast
Est SE df t p
Contrast -2.333 0.382 9.000 -6.113 0.000
(RepeatedData) |> testComplex(contrast1 = c(1/3, 1/3, 1/3), contrast2 = c(1, 0, 0), labels = c("GrandMean", "L1Only"))
Hypothesis Tests for the Mean Contrasts
Est SE df t p
GrandMean 10.333 0.528 9.000 19.563 0.000
L1Only 8.000 0.447 9.000 17.889 0.000
Contrast -2.333 0.382 9.000 -6.113 0.000